Контент анализ представляет собой мти. Описание метода контент-анализ
» Контент-анализ социология
© О.Т. Манаев
Контент-анализ - описание метода
Контент-анализ (от англ. contens содержание) - метод качественно-количественного анализа содержания документов с целью выявления или измерения различных фактов и тенденций, отраженных в этих документах. Особенность контент-анализа состоит в том, что он изучает документы в их социальном контексте. Может использоваться как основной метод исследования (например, контент-анализ текста при исследовании политической направленности газеты), параллельный, т.е. в сочетании с другими методами (напр., в исследовании эффективности функционирования средств массовой информации), вспомогательный или контрольный (напр., при классификации ответов на открытые вопросы анкет).
Не все документы могут стать объектом контент-анализа. Необходимо, чтобы исследуемое содержание позволило задать однозначное правило для надежного фиксирования нужных характеристик (принцип формализации), а также, чтобы интересующие исследователя элементы содержания встречались с достаточной частотой (принцип статистической значимости). Чаще всего в качестве объектов исследования контент-анализа выступают сообщения печати, радио, телевидения, протоколы собраний, письма, приказы, распоряжения и т.д., а также данные свободных интервью и открытые вопросы анкет.
Основные направления применения контент-анализа: выявление того, что существовало до текста и что тем или иным образом получило в нем отражение (текст как индикатор определенных сторон изучаемого объекта - окружающей действительности, автора или адресата); определение того, что существует только в тексте как таковом (различные характеристики формы - язык, структура, жанр сообщения, ритм и тон речи); выявление того, что будет существовать после текста, т.е. после его восприятия адресатом (оценка различных эффектов воздействия).
В разработке и практическом применении контент-анализа выделяют несколько стадий. После того, как сформулированы тема, задачи и гипотезы исследования, определяются категории анализа - наиболее общие, ключевые понятия, соответствующие исследовательским задачам. Система категорий играет роль вопросов в анкете и указывает, какие ответы должны быть найдены в тексте. В практике отечественного контент-анализа сложилась довольно устойчивая система категорий - знак, цели, ценности, тема, герой, автор, жанр и др. Все более широко распространяется контент-анализ сообщений средств массовой информации, основанный на парадигматическом подходе, в соответствии с которым изучаемые признаки текстов (содержание проблемы, причины ее возникновения, проблемообразующий субъект, степень напряженности проблемы, пути ее решения и др.) рассматриваются как определенным образом организованная структура.
Категории контент-анализа должны быть исчерпывающими (охватывать все части содержания, определяемые задачами данного исследования), взаимоисключающими (одни и те же части не должны принадлежать различным категориям), надежными (между кодировщиками не должно быть разногласий по поводу того, какие части содержания следует относить к той или иной категории) и уместными (соответствовать поставленной задаче и исследуемому содержанию). При выборе категорий для контент-анализа следует избегать крайностей: выбора слишком многочисленных и дробных категорий, почти повторяющих текст, и выбора слишком крупных категорий, т.к. это может привести к упрощенному, поверхностному анализу. Иногда необходимо принимать во внимание и отсутствующие элементы текста, которые могут быть значимыми для контент-анализа.
После того, как категории сформулированы, необходимо выбрать соответствующую единицу анализа - лингвистическую единицу речи или элемент содержания, служащие в тексте индикатором интересующих исследователя явления. В практике отечественных контент-аналитических исследований наиболее, употребительными единицами анализа являются слово, простое предложение, суждение, тема, автор, герой, социальная ситуация, сообщение в целом и др. Сложные виды контент-анализа обычно оперируют не одной, а несколькими единицами анализа. Единицы анализа, взятые изолировано, могут быть не всегда правильно истолкованы, поэтому они рассматриваются на фоне более широких лингвистических или содержательных структур, указывающих на характер членения текста, в пределах которого идентифицируется присутствие или отсутствие единиц анализа - контекстуальных единиц. Например, для единицы анализа «слово» контекстуальная единица - «предложение». Наконец, необходимо установить единицу счета - количественную меру взаимосвязи текстовых и внетекстовых явлений. Наиболее употребительны такие единицы счета, как время-пространство (число строк, площадь в квадратных сантиметрах, минуты, время вещания и т.п.), появление признаков в тексте, частота их появления (интенсивность).
Важен выбор необходимых источников, подвергаемых контент-анализу. Проблема выборки содержит в себе выбор источника, количества сообщений, даты сообщения и исследуемого содержания. Все эти параметры выборки определяются задачами и масштабами исследования. Чаше всего контент-анализ проводится на годичной выборке: если это изучение протоколов собраний, то достаточно 12 протоколов (по числу месяцев), если изучение сообщений средств массовой информации - 12-16 номеров газеты или теле-, радиодней. Обычно выборка сообщений средств массовой информации составляет 200-600 текстов.
Необходимым условием является разработка таблицы контент-анализа - основного рабочего документа, с помощью которого проводится исследование. Тип таблицы определяется этапом исследования. Например разрабатывая категориальный аппарат, аналитик составляет таблицу, представляющую собой систему скоординированных и субординированных категорий анализа. Такая таблица внешне напоминает анкету: каждая категория (вопрос) предполагает ряд признаков (ответов), по которым квантифицируется содержание текста. Для регистрации единиц анализа составляется другая таблица - кодировальная матрица. Если объем выборки достаточно велик (свыше 100 единиц), то кодировщик, как правило, работает с тетрадью таких матричных листов. Если выборка невелика (до 100 единиц), то можно проводить двумерный или многомерный анализ. В этом случае для каждого текста должна быть своя кодировальная матрица. Эта работа трудоемка и кропотлива, поэтому при больших объемах выборки сопоставление интересующих исследователя признаков осуществляется на компьютере.
Важным условием контент-анализа является разработка инструкции кодировщику - системы правил и пояснений для того, кто будет собирать эмпирическую информацию, кодируя (регистрируя) заданные единицы анализа. В инструкции точно и однозначно излагается алгоритм действий кодировщика, дается операциональное определение категорий и единиц анализа, правила их кодирования, приводятся конкретные примеры из текстов, являющихся объектом исследования, оговаривается, как следует поступать в спорных случаях, и т.д. Процедура подсчета при количественном контент-анализе в общем виде аналогична стандартным приемам классификации по выделенным группировкам ранжирования и измерения ассоциации. Существуют также специальные процедуры подсчета применительно к контент-анализу, напр., формула коэффициента Яниса, предназначенного для вычисления соотношения положительных и отрицательных (относительно избранной позиции) оценок, суждений, аргументов. В случае, когда число положительных оценок превышает число отрицательных,
Введение
1. Документальные источники информации
1.1 Классификация документов
1.2 Достоверность документальной информации
1.3 Приемы качественно- количественного анализа документов
2. Контент-анализ как метод анализа документов
2.1 Общая характеристика метода контент-анализа
2.2 Основные процедуры контент-анализа
2.3 Процедуры подсчета
3. Оценка метода документального анализа
3.1 Надежность информации полученной с помощью контент-анализа
3.2 Оценка метода документального анализа
3.3 Контент-анализ газетных материалов (события в Беслане)
Заключение
Список используемой литературы
Приложение
Введение
В истории социологии известен факт, когда основой исследования послужили в основном личные документы. В начале века американский социолог У. Томас и польский - Ф.Знанецкий предприняли кропотливое изучение личных документов польских эмигрантов с тем, чтобы описать их положение в Европе и Америке. В числе использованных документов были: переписка крестьян-эмигрантов с родными, оставшимися в Польше; архивы эмигрантских газет; материалы церковно-приходских общин, землячеств, благотворительных обществ и судебные материалы, связанные с делами эмигрантов; наконец, уникальная автобиография одного из крестьян, написанная по просьбе исследователей и составившая около 300 страниц.
Отчего реальный человек, в особенности "маленький человек", оказывается неинтересным для отечественного исследователя? Эта ситуация не вполне адекватна потребностям социального знания, особенно, если иметь в виду вопрос, выдвинутый еще М. Вебером в рамках его теории действия: "Какие мотивы заставляли и заставляютотдельных "функционеров" и членов данного "сообщества", вести себя таким образом, чтобы подобное сообщество возникло и продолжало существовать!". Без ответа на него невозможно понять, как возникло и существовало почти целый век советское общество, как и почему это общество прекратило свое существование.
Любое социальное изменение происходит тогда, когда действие перестает ориентироваться на представление о действенности данного социального порядка. Всякий порядок кристаллизуется, когда возникает и постоянно воспроизводится вера в такую действенность. Своими действиями актеры социальной драмы воспроизводят и изменяют сами условия действия. Свойства социальной системы лишь в ограниченной степени зависят от сознания и воли индивидов. Однако направленность социальных процессов не может не быть вызвана повседневными действиями, повседневными решениями множества рядовых социальных агентов, их активностью. Иначе общество бы попросту не существовало. Обращение к заметкам, письмам, дневникам рядовых агентов исторического процессавполне правомерно и не носит факультативного характера.
Очень важный вопрос: что мы при этом исследуем? Некоторое время назад ответ был бы, скорее всего, таким: массовое сознание. Нынче на этот вопрос отвечаешь по-иному. Скорее, мы исследуем индивидуальное. Проблема индивидуального никогда не воспринималась как простая. Недаром даже методы наук были некогда поделены на номотетические и иднографические. Споры о проблемах исследования индивидуального продолжаются по сей день.
Целью данного курсовой работы является изучение контент-анализа как метода исследования в СГМУ.
Задачи курсовой работы следующие:
1. Рассмотреть, что такое документальные источники информации.
2. Изучить контент-анализ как метод анализа документов.
3. Рассмотреть основные процедуры контент-анализа.
4. Оценить метод документального анализа.
Цель этой работы достигалась с помощью системного анализа, синтеза, аналогии и др. методов.
Исследовательская база: учебная литература для ВУЗов, журнальные статьи и др.
1. Документальные источники информации
1.1 Классификация документов
Документальной в социологии называют любую информацию, фиксированную в печатном или рукописном тексте, на магнитной ленте, на фото- ими кинопленке.В этом смысле значение термина отличается от общеупотребительного: обычно документом мы называем лишь официальные материалы.
По способу фиксирования информации различают: рукописные и печатные документы; записи на кино-ил и фотопленке, на магнитной ленте. С точки зрения целевого назначения выделяются материалы, которые были провоцированы самим исследователем (к примеру, биография эмигранта в работе Томаса и Знанецкого). Эти документы называют целевыми.Но социолог имеет дело и с материалами, составленными независимо от него, ради каких-то других целей, т. е. с наличными документами. Обычно именно эти материалы и называют собственно документальной информацией в социологическом.
По степени персонификации документы делятся на личныеи безличные. К личным относят карточки индивидуального учета (например, библиотечные формуляры или анкеты и бланки, заверенные подписью), характеристики и рекомендательные письма, выданные данному лицу, письма, дневники, заявления, мемуарные записи. Важный источник изучения политической жизни - документы поименного голосования в представительных органах власти.
Безличные документы - это статистические или событийные архивы, данные прессы, протоколы собраний.
В зависимости от статуса документального источника выделим документы официальныеи неофициальные.К первым относятся правительственные материалы, постановления, заявления, коммюнике, стенограммы официальных заседаний, данные государственной и ведомственной статистики, архивы и текущие документы различных учреждений и организаций, деловая корреспонденция, протоколы судебных органов и прокуратуры, финансовая отчетность и т. п.
Неофициальные документы - это многие личные материалы, упомянутые выше, а также составленные частными гражданами безличные документы (например, статистические обобщения, выполненные другими исследователями на основе собственных наблюдении).
Особую группу документов (к ним мы еще вернемся) образуют многочисленные материалы средств массовой информации: газет, журналов, радио, телевидения, кино, видеоматериалы.
Наконец, по источнику информации документы разделяют на первичныеи вторичные.Первичные составляются на базе прямого наблюдения или опроса, на основе непосредственной регистрации совершающихся событий. Вторичные представляют обработку, обобщение или описание, сделанное на основе данных первичных источников.
Помимо этого, можно, конечно, классифицировать документы по их прямому содержанию, например литературные данные, исторические и научные архивы, архивы социологических исследований, видеохроники общественных событий.
1.2Достоверность документальной информации
Не следует смешивать надежность, подлинность самого документа с достоверностью сообщаемых в нем сведений.
Целевые документы, запланированные исследователем, будут надежны в случае, если предусмотрены обычные операции контроля, рассмотренные выше: поиск независимого источника информации (для выборочного контроля), вторичные обращения к тому же источнику (устойчивость данных), тесты по известным группам.
Документалисты-историки и психологи выработали немало приемов, с помощью которых определяют степень достоверности сведений, судя по самому содержанию документальной информации.
Первое "золотое правило" в работе с документами (да и вообще со всякой информацией) - четко различать описания событий и их оценку. Мнения и оценки потенциально обладают меньшей достоверностью и надежностью по сравнению с фактуальной информацией. Нередко в документе отсутствует детальная характеристика ситуации, о которой высказано мнение или оценка. Но именно конкретная ситуация дает ключ к расшифровке смысла высказанных оценок и мнений.
Далее следует проанализировать, какими намерениями руководствовался составитель документа, что поможет выявить умышленные пли непроизвольные искажения. К примеру, автор отчета о проделанной работе, как правило, склонен обрисовывать ситуацию в благоприятном для себя свете. Но если мы для сбора информации воспользуемся, скажем, отчетами проверочных комиссий, картина будет другой. Целевая установка подобных документов предрасполагает к обнаружению как раз упущений и недостатков, негативных сторон деятельности.
Очень важно знать, каков метод получения первичных данных, использованный составителем документа. Всем известно, что сведения "из первых рук" надежнее, чем информация из неопределенного источника ("некоторые утверждают, что..."), а записи по свежим впечатлениям отличаются от описания тех нее событий спустя какое-то время.
Если документ содержит статистическую группировку данных, следует в первую очередь выявить основание классификации. В соответствии с целью исследования возможны перегруппировки данных по иным основаниям.
Наконец, чрезвычайно важно хорошо уяснить общую обстановку, в которой составлялся документ: располагала ли она к объективности (независимо от целевых намерений автора) или диктовала смещение информации в какую-то сторону?
Особую осторожность должен проявить исследователь при работе с личными документами, такими, как автобиографии, дневники, мемуары, письма и т. п. Вот несколько условий доверия к информации из личных документов.
(а) Можно верить сообщениям, если они никак не затрагивают интересы автора документа; или (б) наносят определенный ущерб автору; (в) видимо, достоверны те сведения, которые в момент "регистрации автором были общеизвестны; (г) достоверны детали событий, несущественные с точки зрения автора документа, а также (д) сведения, к которым автор относится недоброжелательно. Проверка подлинности документа, анализ мотивов, побуждений, условий его составления, целевой установки автора, ситуации, в которой он действовал, характера егоокружения - вот те факторы, от которых зависит достоверность информации из личных документов.
Традиционный (классический) анализ документов в отличие от простого ознакомления с ними или прочтения для приобретения нового знания - это именно метод исследования, которое, как всякое научное исследование, предполагает выдвижение определенных гипотез, тщательной изучение существа анализируемого материала, логики текста, обоснованности и достоверности приводимых сведений. Этот анализ "стремится как бы до конца проникнуть в глубь документа, исчерпать его содержание. Традиционный анализ есть анализ интенсивный" Добавим, что огромную роль играют здесь опыт исследователя, глубина его знаний по предмету и интуиция.
1.3 Приемы качественно- количественного анализа документов.
Основная трудность при работе с доступными (т. е. нецелевыми) документами - умение читать данные на языке гипотез исследования. Ведь документ был составлен вовсе не для того, чтобы проверить гипотезы социолога. Поэтому, прежде чем анализировать документальные материалы по существу, социолог вынужден проделать утомительную работу поиска в документе индикаторов (признаков) ключевых понятий исследования.
Качественный анализ документов - необходимое условие для всех количественных операций. Но прежде следует заметить, что квантификации текстов далеко не всегда целесообразна.
В каких случаях не следует прибегать к количественному анализу?Видимо, это неразумно, если мы имеем дело с уникальными документами, где главная цель изучения - всесторонняя содержательная интерпретация материала. Не следует обращаться к количественному анализу, если перед нами описания весьма сложных явлений, если документальных данных недостаточно для массовой обработки или они неполные (нерепрезентативны).
Когда количественный анализ текстов уместен?Прежде всего, отмечает один из основателей этого метода Б. Берельсои, если требуется высокая степень точности при сопоставлении однопорядковых данных. Далее, когда достаточно много материала, чтобы оправдать усилия, связанные с его количественной обработкой, и если этот материал репрезентирует области изучения. Квантификация необходима, когда текстового материала не только достаточно, но столь много, что его нельзя охватить без суммарных оценок. Квантификация возможна при условии, что изучаемые качественные характеристики появляются с достаточной частотой.
Наиболее целесообразно использовать количественный анализ, если квалифицированные тексты сопоставляются с иными, также количественными характеристиками. Например, выраженные в статистических распределениях особенности содержания газетных сообщений сопоставляются с численностью подписчиков, их мнениями об этих материалах, тоже выраженными в числах.
Квантификация текстового материала получила весьма широкое распространение, и в 40-х гг. для нее была разработана специальная процедура, названная "контент-анализ".
Контент-анализ - это перевод в количественные, показатели массовой текстовой (или записанной на пленку) информации с последующей статистической ее обработкой.Его основные операции были разработаны американскими социологами X. Лассуэллом и Б. Берельсоном. Важный вклад в развитие процедур контент-анализа внесли российские и эстонские социологи, особенно А.Н. Алексеев, Ю. Вооглайд, П. Вихалемм, Б.Л. Грушин, Т.М. Дридзе, М. Лауристинь.
2. Контент-анализ как метод анализа документов
2.1 Общая характеристика метода контент-анализа
Контент-анализ - это техника сбора информации, производимого на основе систематического выявления соответствующих целям и задачам исследования характеристик текстов (понятий, глаголов, словосочетании и пр.). Контент-анализ предполагает использование определенных стандартизированных процедур, обеспечивающих формализацию и измерение исследуемых признаков, что позволяет делать профессиональные заключения о характере и особенностях изучаемого объекта. Особенно эффективно использование контент-анализа при исследовании программ политических партий и движений, когда по ключевым понятиям и словосочетаниям можно составить представление об отличительных особенностях каждой из них. К примеру, использование контент-анализа позволяет на основе подсчета слов, фотографий или газетных столбцов, посвященных тому ли иному кандидату в депутаты, определить его рейтинг в средствах массовой информации.
Контент-анализ может быть содержательным и структурным. Содержательный контент-анализ сосредоточивает внимание исследователя на содержании сообщения, тогда как структурный - на количестве и особенностях упоминания контрольного термина или имени в тексте сообщения.
Основными задачами контент-анализа являются.
1.Выявление и оценка характеристик текста как признаков отдельных сторон исследуемого объекта.
2.Выяснение причин или условий, повлиявших на соответствующие особенности текстового сообщения.
3.Оценка эффекта воздействия сообщения на аудиторию, установление адресных точек такого воздействия.
Проведение контент-анализа может быть эффективным, если в ходе соответствующей процедуры будет использован специальный кодировальный бланк, образец которого представляет собой Приложение 1.
Контент-анализ Применяется при исследовании разного рода публикаций политического характера, опубликованных договоров, программ политических партий, радио- и телепередач и т.д. В данных материалах так или иначе отражается реальная действительность, в том числе политическая, которая и подвергается анализу.
Считается, что с помощью этого метода можно более объективно исследовать происходящие политические явления и процессы.
Исследование начинается с анализа текстов, в которых содержится информация об указанных явлениях и процессах. Прежде всего выделяются соответствующие смысловые единицы;определенные сведения, количественные показатели, оценки, понятия, раскрывающие содержание того или иного политического текста и, следовательно, отражаемого им политического явления. Поскольку содержащиеся в тексте сведения, оценки, понятия выражаются определенными терминами и характерными словосочетаниями, они также учитываются при контент-анализе.
Таким образом, контент-анализ начинается с логической, лингвистическойи другой формализации изучаемого текста (в данном случае текста политического содержания). Поскольку чаше всего исследуются большие массивы информации, порой весьма сложные, то выделяется множество смысловых единиц и разрабатывается соответствующий математический аппарат их количественного анализа.
Тем самым контент-анализ является методом качественно-количественного изучения текстов с присущими ему процедурами формализации исследуемого материала. Выделенные смысловые единицы подвергаются соответствующим математическим операциям.
Например, подсчитывается число упоминаний тех или иных смысловых единиц, выступающих в качестве единиц счета, а также число выражающих их терминов, словосочетаний; количество текста, относящегося к той или иной смысловой единице, или затраченное на ее упоминание количество времени радио- или телевизионного вещания и т.д. Полученные массивы информации (нередко весьма большие) обрабатываются с помощью современной вычислительной техники.
Контент-анализ политических текстов способствует более глубокому пониманию не только непосредственного содержания этих текстов, но и того, что сказано «между строк». Кроме того, становится яснее политическая, идеологическая и иная позиция авторов данных текстов.
Метод контент-анализа политических документов и иных текстов все чаще применяется в исследовании политических явлений и процессов.
2.2 Основные процедуры контен-анализа
смысловых единиц,
(а) Понятия, выраженные в отдельных терминах. Это могут быть понятия из области экономики: формы собственности, приватизация, финансовая система, технический прогресс, оптимизация управления и др.; термины политического содержания; правящие круги и оппозиция, империализм или национализм, авторитаризм, демократия, международное сотрудничество, консенсус, конфликт интересов; нравственные или правовые символы: права человека, гуманизм, активность, инициативность, деловая предприимчивость, нарушение законности, преступность, коррупция; научные: модель, система, космическое пространство и т. п. Очевидно, что анализ текста по содержанию понятий несет немало важной социальной информации. Например, по частоте употребления понятий, связанных с наукой и новой техникой, можно определить, в какой мере источник информации ориентирован на научно-техническую модернизацию.
(б) Тема, выраженная в целых смысловых абзацах, частях текстов, статьях, радиопередачах и т. п.
По тематике можно еще более полно представить содержание документа.
(в) Имена исторических личностей, политиков, выдающихся ученых и деятелен искусства, организаторов производства, лидеров движений и партий, наименования общественных институтов, организации и учреждений.
Эти характеристики могут свидетельствовать о влиянии отдельных лиц или представляемых ими социальных институтов, сообществ, групп на общественное мнение. По числу ссылок на отдельных авторов определяют значимость той или иной научной идеи: если число ссылок растет или падает, это свидетельствует о росте или падении авторитета данной концепции. По частоте упоминаний общественных движений или их лидеров легко заключить о влиятельности этих движений.
(г) Целостное общественное событие, официальный документ, факт, произведение, случай и т. п. несут специфическую смысловую нагрузку и тоже могут быть приняты за единицу анализа. Частота и длительность (во времени) упоминания общественного события или государственного решения - свидетельство его важности для общества.
(д) Смысл апелляций к потенциальному адресату - пользователю рекламируемой продукции, или гражданину как возможному стороннику политического, иного движения. В коммерческой рекламе содержатся апелляции к возрастным когортам (например, "молодежь выбирает..."), социальному слою, активирующие разные потребности личности (здоровье, социальный статус...), нацеленные на мотивацию избежания опасности или достижение успеха и т. д. В политической рекламе, как правило, единицами анализа могут выступать апелляции к определенным ценностям (справедливости, разумности и, добру), к нравственным нормам и стремлениям обустроить жизнь лучшим образом и т.д.
Рассмотрим, как, например, фиксировалось содержание информации по проблемам международной жизни (центральные и местные газеты)
(а) Частота информации определяется как частота упоминания данной страны или проблемы, указанных в разделе "в", частота положительных-отрицательных оценок (раздел "г") и частота описательно-оценочной информации (раздел "д").
(б) Объем информации фиксируетсядвумя единицами: по числу строк текста и по удельному весу информации о данной стране в общем объеме газетного текста.
(г) Итак информации определяется как "положительное" и "отрицательное", "сбалансированное" и "нейтральное" отношения, что соответственно кодируется как +, -, ±, 0.
(д) Тип и характер информации: 1. Фактографическая, содержащая сведения, полученные из неопределенного источника (источник не укалывается); 2. Комментаторская: оценка фактов, свидетелем которых" был автор сообщения; 3. Комментаторская: оценки фактов, свидетели которых не указываются;
4.Художественно-фактографическая: типа очерков, зарисовок "с натуры" (1) участием автора пли с указанием источника;
5.Художественно-фактографическая: типа безадресных очерков с упоминанием событий, реальность которых сомнительна;
6. Общетеоретическая информация иностранных авторов, не содержащая ссылок на конкретные факты; 7. Аналогия предыдущей - советских авторов; 8. Абстрактно-художественная: безадресные стихи, рассказы и т. п. иностранных авторов; 9. Та же советских авторов.
Далее по каждому из этих пунктов разрабатывается подробная инструкция с указанием правил отнесения материалов в рубрику по индикаторам газетного текста. Например, при определении знака информации инструкция требует от кодировщика определять знак "не на основе собственных впечатлений от текста (тем более не на основе привычных традиционных для средств массовой коммуникации способов освещения того или иного вопроса), но исключительно на основе видимым образом (и лексике текста) выраженного отношения коммуникатора к проблеме". Дается инструкция по тематике и "знаку" информации, например, о позиции в вопросах войны и мира. Кодировать "+": "...выступает за сохранение мира на земле..."; кодировать "±": "...Занимает в вопросах войны и мира нейтральную позицию..."; кодировать "-"; "...Создает обстановку военного напряжения".
Закодированный по детальной инструкции текст заносится в шифрованный лист и далее подвергается статистической обработке.
2.3 Процедуры подсчета
В общем виде процедуры подсчета при контент-анализе аналогичны стандартным приемам классификации по выделенным группировкам, ранжирования и шкального изменения. Например, изучая тематику газеты, мы произведем процентовку по сгруппированным смысловым единицам разного содержания. Можно предпринять перекрестную классификацию (содержание выдвигаемых идей, средства, предложенные для их осуществления, аргументы).
По такой таблице целесообразно получить коэффициент энтропии распределения (Е) и коэффициент ассоциации (?*). Мы увидим, в какой мере та или другая группа идей связана со специфической аргументацией и средствами реализации идеи.
Для исчисления результатов контент-анализа используются и специально разработанные формулы.
Так, А. Н. Алексеев предложил формулу оценки "удельного веса" смысловых категорий в общем объеме текста. Формула указывает на уровень интенсивности представленной в тексте определенной темы (или аргументации, способов обращения к читателю и т. д.). Эта формула:
Укс=Кгл+Квт/∑(2Кгл+Квт)*100%
Где Укс-- "удельный вес" данной смысловой единицы; Кгл - число случаев, когда смысловая единица оказалась главной; Квт - число случаев, когда та же единица оказывается второстепенной; ∑ - сумма анализируемых текстов (документов).
Применяются также статистические расчеты доходчивости текста (терминов, предложений), его интересности для читателя и более сложные приемы изучения взаимосвязи распределений смысловых единиц.
Техника контент-анализа находит широкое распространение в социальных исследованиях.
Большой эффективности при использовании контент-анализа добились в 60-е гг. эстонские социологи, работавшие в сотрудничестве с газетой "Эдази" в Тарту (руководитель исследований Юло Вооглайд). Содержание газеты подвергалось ежедневному контент-анализу по специальной программе, данные заносились на перфокарты, приспособленные для ручной обработки, и еженедельно обобщались на редакционных совещаниях. Результат - повышение оперативности, обогащение содержания, удвоение тиража районной газеты за счет подписчиков по всей республике.
Применявшийся вначале для изучения эффективности массовой пропаганды, этот прием стал ныне сильным средством анализа всевозможных официальных и неофициальных документов. Контент-анализ применяют также в практике изучения писем, поступающих в различные организации и органы управления, в политологии, социальной психологии и педагогике, в криминологии, искусствоведении, этнографии и т. д. Крайне трудоемкие процедуры обработки данных контент-анализа существенно облегчаются компьютерными программами (они входят в комплект SPSS и имеются в виде специальных разработок). Благодаря расширяющемуся применению персональных компьютеров и введению в их память текстовой информации появилась возможность намного интенсивное использовать контент-анализ ответов респондентов на открытые вопросы в анкетах. Политологические исследования широко используют эту технику при изучении политических документов, программ общественных движении, видеозаписей массовых собраний, съездов, митингов и т. п.
3. Оценка метода документального анализа
3.1 Надежность информации полученной с помощью контент-анализа
Надежность информации, получаемой контент-анализом, обеспечивается следующими способами:
а) Обоснование полноты объема выделяемых смысловых единиц методом "снежного кома". Это делается следующим образом. Первоначально выделяются все смысловые единицы из первого анализируемого текста, далее из второго текста - те же плюс дополнительные, ранее не встречавшиеся, из третьего документа- опять те же, что уже встречались в двух предыдущих, плюс дополнительные и т. д. После изучения очередных 3-5 текстов, а которых уже не попадается ни одной новой единицы, ранее фиксированной в предыдущих документах, можно полагать, что «поле» смысловых единиц из изучаемого массива исчерпано.
В итоге изучения 20 случайно отобранных из всего массива текстов было выделено суммарно 120 единиц контент-анализа, что исчерпывает "поле", т. е. всю выборочную совокупность документов. Конечно, при изучении всего массива могут попасться новые смысловые единицы, относящиеся к предмету и ранее не предусмотренные. В этом случае они включаются в анализ дополнительно.
б) Контроль на обоснованность содержания смысловых единиц с помощью судей. Специалисты в данной области обсуждают, насколько предложенные качественные единицы соответствуют поставленным задачам.
В нашем исследовании 6 экспертов независимо друг от друга к классифицировали 120 понятий, отнесенных к деловым и личностным качествам инженера, в 6 общих категории (творческие качества, исполнительские и т.д.), причем 86 % понятий были классифицированы однозначно минимум четырьмя судьями. Остальные, более спорные, подвергались спечиальному обсуждению и после согласованного решения относились к соответствующую общую категорию.
и) Обоснованность по независимому критерию. Например, данные контент-анализа дневников или сочинений учащихся с целью выявить их профессиональную склонность выборочно проверяются путем опросов, или по данным наблюдений, или тестом по известной группе, г) Устойчивость данных определяется при помощи кодирования одного текста разными кодировщиками на основе единой инструкции. Можно использовать стабильную единицу анализа и разные единицы счета (по частотам смысловых единиц и по физической протяженности одновременно).
3.2 Общая оценка метода документального анализа
Документы нередко выступают в качестве главного источника информации, дополняемой опросом или прямым наблюдением. Обычно это материалы прессы, а также письма читателей, статистические отчеты, карточки персонального учета (например, библиотечные формуляры при изучении читательского спроса), административные инструкции, рекламные тексты, политические листовки и т.д.
Использование личных, или, как иногда говорят, "человеческих", документов, в теоретической парадигме жесткого, например, структурно-функционального, анализа более ограниченно. Такие материалы хороши для социально-психологических и педагогических исследований. Личные документы - прекрасная база для жанра социологического эссе, широко используемого нашими польскими коллегами. Большой популярностью пользуются в Польше своеобразные конкурсы сочинений или биографий, объявляемые через газету. Итоги анализа таких материалов публикуются в виде полусоциологичос-ких-полужурналистских очерков, ставящих подчас весьма острые и серьезные проблемы.
И напротив, в интерпретационных теоретических подходах (феноменологических, культурологических) жизненные истории, биографии - великолепный источник изучения социальных процессов и обыденных практик людей.
Социолог должен проявить недюжинную изобретательность в поисках подходящих документов, подчас весьма неожиданных.
Советский демограф В.И. Переведенцев остроумно проверил гипотезу о влиянии этнических факторов на миграцию населения. Он сопоставил данные об интенсивности миграции коренного населения союзных республик с данными Всесоюзной переписи 1959 г. о доле, лиц коренной национальности (по республикам), не считающих язык своей национальности родным языком. Оказалось, что эти пропорции совпадают почти идеально. Так, интенсивность миграции украинцев (в пропорции к русским) 11%, а доля украинцев, не говорящих на родном языке, - 12,3%, для белорусов - соответственно 15% против 15,8%, для народов Закавказья - 5% против 4,6%, народов Средней Азии - около 1% против 1,5%, для казахов -- 4% против 1,6%, для народов Прибалтики - 4% против 3,5%. Очевидно, что этнический фактор существенно влиял па миграцию.
Главные недостатки описанного метода состоят в отмеченных выше проблемах получения достоверной информации из биографических материалов и в том, что при изучении человеческой деятельности в документах часто отражается не процесс, но лишь результаты.
Анализ документов - важный метод сбора информации при формулятивномплане исследования (для выдвижения гипотез и, общей разведки темы) и на стадии работы по описательному плану. В экспериментальных исследованиях возникают значительные трудности перевода языка документов на язык гипотез, но, как показывает опыт, и эти затруднения можно преодолеть при умелом обращении с материалом.
Наконец, огромное и вполне самостоятельное значение имеют для социолога данные государственной политики, которыми надо уметь пользоваться, а так же знать с какой регулярностью они собираются и публикуются.
3.3 Контент-анализ газетных материалов (события в Беслане)
Борьба за смыслы, образы, акценты понимания событий, за установки и ориентации масс обостряется с ростом неопределенности общественной ситуации. Неопределенность возрастает в периоды, предшествующие поворотным моментам истории. Разрешение ситуации неопределенности приводит к тому, что политический победитель навязывает свой смысл или буквально "пишет историю". Однако есть события, которые не являются публично подготовленными и которые случаются относительно неожиданно или неожиданны по своим масштабам и глубине воздействия. Такими событиями являются теракты. Борьба за смыслы и акценты этих событий разворачивается сразу после их совершения. Таким событием стал теракт в Беслане.
При внешней схожести отношений различных СМИ к этому теракту можно обнаружить определенные различия. Они выявлялись с помощью количественного контент-анализа публикаций. В выборке, подвергнутой анализу, представлены все статьи и материалы "Независимой газеты", "Коммерсанта", "Советской России", в которых содержится слово "Беслан" с 1 по 17 сентября 2004 г. Статьи снимались с Интернет-сайтов газет автоматическим образом. Объем статейного материала различается по газетам в связи с разными объемом газет, частотой выхода газет и вниманием к событиям: "Независимая газета" - 154 статьи, 0,8 мегабайт информации, "Коммерсант" -48 статей, 0.4 мегабайта информации, "Советская Россия" - 27 статей, 0.2 мегабайта. При анализе относительное сравнение проводилось с выравниванием данных. Использовалась компьютерная программа "Контент-вижн" (автор Вирник Ю.П.).
Рассматривалась только частота использования тех или иных слов, без оценки контекста их использования, т.е. не проводилось дополнительного исследования, как подаются те или иные слова - в позитивном или негативном значении.
1. Смысловой ряд противостояний "мы" - "они" у газет различается не очень значительно. Наиболее склонны к объединению "мы" авторы "Коммерсанта", затем "Независимой газеты". Авторы "Советской России" и ее подразумеваемые читатели "мы" не склонны объединяться с кем-либо в борьбе с "они", тогда как претензии на окружающий мир у них значительно больше, чем у авторов других газет, они ярко ощущают себя и свой мир пострадавшим в результате теракта (ряд слон "наш" выбивается из общего ряда в сторону увеличения).
Превалирование "мы" над "они" создает эмоциональный фон, ориентирующий читателей на возможность преодоления негативного, на "нашу" победу над "ними".
4. Наиболее эмоционально негативно настроенной к террористам можно признать "Советскую Россию". Ряд "Подонки \ убийцы \ сволочи \ убдюдки \ нелюди \ твари встречается в пропорционально представленном тексте наиболее часто. Затем следуют "Коммерсант", "Независимая газета". 3."Советская Россия" наиболее негативно относится к тем, кто совершал акцию в Беслане, используя негативный ряд "террористы \ бандиты" в три раза чаще, чем относительно нейтральный "боевики \ сепаратисты \ шахиды \ басаевцы \ захватчики".Независимая газета" ряд "террористы \ бандиты" использует в два с половиной раза чаще относительно нейтрального ряда "боевики \ сепаратисты \ шахиды \ басаевцы \ захватчики". "Коммерсант" стремится к уравновешиванию негативных и нейтральных рядов при некотором превалировании негативных характеристик 4.Наиболее склонна к интерпретации событий в этнонациональных категориях газета "Коммерсант", ее авторы склонны видеть причины трагедии и конфликта в деятельности различных народов: осетин, ингушей, чеченцев, русских. "Коммерсант" практически не использовал обобщенного понятия "россияне", описывая события. Наиболее интернационалистична и даже этнобезразлична "Советская Россия". В ней названия народов: осетин, ингушей, чеченцев, русских - все вместе встречаются почти также часто (12 раз), как и слово "россияне" (9 раз). "Независимая газета" приоритеты расставила так: русские, чеченцы, ингуши, осетины. "Россияне" только в шесть раз встречаются реже, чем названия всех четырех народов.
5. Религиозные причины событий интересуют в первую очередь "Независимую газету", примерно в два раза реже пропорционально имеющимся материалам, чем "Коммерсант" и "Советская Россия".
6. Понятие "война" на единицу текста чаще других использует "Советская Россия". Ряд понятия "терроризм" используется значительно чаще относительно более нейтрального ряда "теракт \ захват", «Независимая газета" тоже достаточно часто использует понятие "война" и ее производные, тогда как "Коммерсант" менее всех склонен применять понятие "война" к оценке описываемых событий. Эта газета относительно чисто использовала более нейтральные "захват" и "теракт".
7. "Советская Россия" частотно склонна ассоциативно связывать произошедшие события с действиями "властей \ чиновников", в четыре раза чаще "Независимой газеты" и в пять раз чаще "Коммерсанта". Интерес к деятельности ряда "спецслужбы \ силовики \ ФСБ \ МВД Ч милиция" по частоте упоминания относительно выражен у "Коммерсанта", затем "Независимой газеты", наиболее низок у "Советской России". 8.В рамках оценок "трагедия \ катастрофа" склонны трактовать события примерно одинаково "Независимая газета" и "Советская Россия". Для "Коммерсанта" частотное использование понятия "трагедия" почти в 15 раз реже.
Количественный контент-анализ дает значимые результаты в дополнение к другим видам анализа: смысловому, качественному контент-анализу и т.д. Вне этого дополнения он ведет к формулированию гипотез, которые могут быть проверены другими способами.
Заключение
Документальной в социологии называют любую информацию, фиксированную в печатном или рукописном тексте, на магнитной ленте, на фото- ими кинопленке.В этом смысле значение термина отличается от общеупотребительного: обычно документом мы называем лишь официальные материалы.
Достоверность информации в первую очередь зависит от источника доступного документа. Разные источники обладают своего рода заведомой степенью достоверности сообщаемых сведений. Во всех случаях первичные данные надежней вторичных. Поэтому официальный личный документ, полученный из первых рук, более надежен и достоверен, чем неофициальный, безличный и к тому же составленный на основе других документов.
При использовании вторичных документов важно установить их первоисточник. Это можно делать выборочно, с тем чтобы оценить общую погрешность вторичных материалов.
Контент-анализ - это перевод в количественные, показатели массовой текстовой (или записанной на пленку) информации с последующей статистической ее обработкой.Его основные операции были разработаны американскими социологами X. Лассуэллом и Б. Берельсоном. Важный вклад в развитие процедур контент-анализа внесли российские и эстонские социологи, особенно А. Н. Алексеев, Ю. Вооглайд, П. Вихалемм, Б. Л. Грушин, Т. М. Дридзе, М. Лауристинь.
Контент-анализ - это техника сбора информации, производимого на основе систематического выявления соответствующих целям и задачам исследования характеристик текстов (понятий, глаголов, словосочетании и пр.). Основными задачами контент-анализа являются.
4.Выявление и оценка характеристик текста как признаков отдельных сторон исследуемого объекта.
5.Выяснение причин или условий, повлиявших на соответствующие особенности текстового сообщения.
6.Оценка эффекта воздействия сообщения на аудиторию, установление адресных точек такого воздействия.
Контент-начинается с выявления смысловых единиц, в качестве которых используют:
Итак, смысловые единицы анализа выделяются на основе содержания гипотез исследования, подсказываются методологическими посылками программы.
Единицы счетамогут и совпадать и не совпадать с единицами анализа. Контент-анализ текста может быть весьма многосторонним, причем одновременно используются несколько единиц анализа и несколько единиц счета.
В общем виде процедуры подсчета при контент-анализе аналогичны стандартным приемам классификации по выделенным группировкам, ранжирования и шкального изменения. Использование личных, или, как иногда говорят, "человеческих", документов, в теоретической парадигме жесткого, например, структурно-функционального, анализа более ограниченно. Такие материалы хороши для социально-психологических и педагогических исследований. Личные документы - прекрасная база для жанра социологического эссе, широко используемого нашими польскими коллегами. Большой популярностью пользуются в Польше своеобразные конкурсы сочинений или биографий, объявляемые через газету. Итоги анализа таких материалов публикуются в виде полусоциологичос-ких-полужурналистских очерков, ставящих подчас весьма острые и серьезные проблемы.
Список используемой литературы
1.Барсамов В. А. Контент- анализ газетных материалов // Социс – 2006 - №2
2. Иванов В.В., Коробова А.Н. Муниципальный менеджмент. Справочник. М.: Инфра-М, 2002.
3. Клуппт М.А. Демографическая политика как предмет контент-анализа // Социологические исследования. 2003. № 6.
4. Козлова Н.Н. Методология анализа человеческих документов // Социологические исследования. 2004.
5. Мангейм Дж. Б., Рич Р.К. Политология. Методы исследования: Пер. с англ. / Предисловие А.К. Соколова. М.: Весь Мир, 1997.
6. Основы прикладной социологии: Учебник для вузов. / Под ред. Ф.Э. Шереги и М.К.Горшкова. М.: Интерпракс, 1996.
7. Рой О. Исследования социально-экономических и политических процессов. СПб: Питер, 2004.
8. Хеллевик О. Социологический метод. М.: Весь мир, 2002.
9. Ядов В.А. Стратегия социологического исследования: описание, объяснение, понимание социальной реальности. М., 1998.
Приложение
Типичный котировальный бланк для проведения структурного контент-анализа
Термин content-analysis впервые начал применяться в конце XIX – начале XX вв. в американской журналистике (см. раб.: Б.Мэттью, А.Тенни, Д.Спиид, Д.Уипкинс). У истоков методологии контент-анализа находились американский социолог Г. Лассуэл и французский журналист Ж.Кайзер.
Так, в начале 60-х гг. Г. Лассуэл осуществил попытку политологического анализа СМИ, исходя из учета формальных критериев. Он ввел в научный оборот некую абстрактную единицу: «слово». Целью работы Лассуэла было получение собственно социологического результата на нетипичном для социологии материале: текстах печатных изданий. Исследователь проделал огромную работу, но, поскольку в методике Лассуэла качественные оценки не были адекватно соотнесены с количественными методами, результаты его трудов с трудом поддавались верификации.
В начале 60-х гг. Ж. Кайзер разработал оригинальную методику статистического анализа периодики. В ее основе лежал подход к тестовому массиву, как информационной системе. Тем самым Кайзер сформулировал теоретическую базу последующего распространения социологических методов в сферы изучения всех нарративных источников, включая эпиграфический и эпистолярный материал. В работе Ж. Кайзера акцентировалось внимание на внешней форме организации материала: его расположении, оглавлении, оформлении и т.д. Кайзер разработал целый комплекс исследовательских процедур, обеспечивающих полную формализацию, как единичного газетного номера, так и совокупности однотипных периодических изданий. Тем самым Ж.Кайзер сформулировал систему, позволяющую фиксировать развитие тенденций в публикациях СМИ.
Свое дальнейшее развитие «кайзеровское направление» методологии контент-анализа получило в работах Э. Морэн. Э. Морен ввела в научный оборот термин «единица информации» - семантический блок, содержание которого отвечает на вопрос: «О чем говориться?» Последнее обстоятельство сделало возможным изучение любых форм организации текстового материала, причем, как на терминологическом уровне, так и на уровне фразы, абзаца, статьи и даже целых книг. Тем самым, Э.Морэн разрушила критерий однородности, применявшийся ранее при статистической обработке нарративов. Взамен, она предложила идеологию «семантических групп», которые, по ее мнению, должны учитываться по тематическому признаку. Кроме того, Э.Морэн разработала концепцию «тона» материала, который определялся социометрически: «положительная информация», «отрицательная», «нейтральная».
Важный вклад в развитие контент-анализа внесли российские и эстонские социологи, особенно А.Н.Алексеев, Ю. Вооглайд, П. Вихалемм, Б.А. Грушин, М. Лауристинь и др.
Для изучения содержания текста традиционно применяется метод контент-анализа. Слово «контент» означает содержимое (или содержание) документа. Под документом при этом понимается не только официальный текст (типа инструкции или правового закона), но все написанное или произнесенное, все, что стало коммуникацией. Так, по словам Ядова В.А., документальной называют любую информацию, фиксированную в печатном или рукописном тексте, на магнитной ленте, на фото- или киноплёнке.
Контент-анализу подвергаются книги, газетные или журнальные статьи, объявления, телевизионные выступления, кино- и видеозаписи, фотографии, лозунги, этикетки, рисунки, другие произведения искусства, а также, разумеется, и официальные документы. В настоящее время в связи с активным использованием электронных средств общения, анализу подвергаются и электронные документы.
Существуют различные определения контент-анализа, некоторые из них не совпадают во взглядах на количественный и качественный аспект метода. Так, существуют две точки зрения на контент-анализ :
Контент-анализ - самостоятельный метод, отличный от обычного содержательного анализа документов
Принципиальное отличие этих методов анализа заключено в явно выраженной строгости, формализованности, систематизированности контент-анализа. Он нацелен на выработку количественного описания смыслового и символического содержания документа, на фиксацию его объективных признаков и подсчет последних.
Федотова Л.Н. выделяет такие присущие методу характеристики: сложность, тщательность, пунктуальность трудоёмкость.
Являясь сторонником данной точки зрения на контент-анализ, В.А.Ядов определяет контент-анализ следующим образом - это перевод в количественные показатели массовой текстовой (или записанной на плёнку) информации с последующей статистической её обработкой.
Вторая точка зрения принимает в расчет оба вида анализа.
Контент-анализ включает в себя как количественный, так и качественный анализ текста.
Первый дополняет второй, а их сочетание углубляет понимание смысла любого текста. Контент-анализ позволяет обнаружить в документе то, что ускользает от поверхностного взгляда при его традиционном изучении, но что имеет важный социальный смысл.
Итак, с точки зрения видов проводимого анализа, выделяется два вида: количественный и качественный контент-анализ. При проведении количественного контент-анализа анализируется частота появления в тексте каких-либо единиц, будь упоминания тем или названий компаний. Определения качественного контент-анализа достаточно размыты, в них чаще всего говорится, что при проведении качественного анализа выводы делаются на основе наличия в тексте какого-либо факта. На самом деле, речь идет об интерпретации содержания текста, которое часто встречается в исторической науке и филологии. По этой причине качественный контент-анализ вернее называть интерпретативным.
В западной исследовательской традиции контент-анализ однозначно рассматривается как количественный метод. Несомненно, что количественный контент-анализ обладает более широкой областью применения и надежностью, чем качественный. Одна из наиболее значимых причин – это объективный характер количественных показателей, в то время как интерпретация почти всегда носит субъективный характер. Впрочем, интерпретация результатов количественного анализа тоже имеет субъективные элементы.
По мнению ряда социологов (Маркоффа, Шапиро, Вейтмана и др.), контент-анализ можно было бы назвать «текстуальным кодированием», так как он предполагает получение количественной информации о содержимом документа на основе ее кодирования.
Итак,количественный контент-анализ в первую очередь интересуется частотой появления в тексте определенных характеристик (переменных) содержания.
Качественный контент-анализ позволяет делать выводы даже на основе единственного присутствия или отсутствия определенной характеристики содержания.
На вопрос: "в каких случаях не следует прибегать к количественному анализу?", В.А. Ядов отвечает: если мы имеем дело с уникальными документами, где главная цель изучения - всесторонняя содержательная интерпретация материала.
От количественных данных качественные отличаются тем, что содержание последних несет в себе смысл, непосредственно характеризующий самого их носителя, в то время как количественные указывают на масштаб, объем, интенсивность характеристик изучаемого явления. Качественные данные позволяют раскрыть значения социального явления, количественные показывают, насколько часто оно случается или насколько интенсивно представлено в социальной реальности. Качественные данные обозначают предмет исследования, количественные - показывают, насколько сильно он проявлен в объекте. Продолжая такого рода рассуждения, можно сделать вывод, что одни данные в большей степени ориентированы на создание суждения о социальном явлении, другие - на оценку значимости или тестирование этого суждения. Эти различия в природе двух типов данных привели к тому, что так называемые качественные исследования (исследования, основанные на сборе и анализе качественных данных) стали связывать в большей степени с этапом генерирования или построения теории, а количественные исследования - с ее верификацией.
То, что качественным методам отводится второстепенная роль, значительно сужает их возможности, по мнению Б. Глезера и А. Страусса, выдвинувших "обоснованную теорию" (grounded theory). Авторы помещают свой метод качественного исследования - "обоснованную теорию" - между подходом контент-анализа и подходом, предлагающим выработку некоторых предварительных идей и гипотез. Классический контент-анализ предлагает следующую модель: сначала задается модель кодировки, а потом данные систематически собираются, оцениваются и анализируются по заранее определенным, неизменным и единым для всех них шкалам, которые позволяют придать качественным (словесным) данным квантифицируемую форму.
Метод Глезера и Страусса предполагает постоянное сравнение и перегруппировку данных. Цель метода постоянного сравнения, в котором объединены кодирование и анализ, - генерирование теории более систематически, чем предполагается во втором подходе, при помощи использования развернутого кодирования и аналитических процедур.
Сравнительный метод используется на каждом этапе аналитического процесса построения обоснованной теории. Он включает в себя следующие процедуры: кодирование, выделение ключевых категорий, теоретический отбор и формирование теоретической выборки, теоретическое насыщение и интеграцию теории.
Этапы контент-анализа
|
Определение задач, теоретической основы и объекта исследования, разработка категориального аппарата, набор соответствующих качественных и количественных единиц. |
|
|
Составление кодировочной инструкции. |
|
|
Пилотажная кодировка текста |
|
|
Кодировка всего массива исследуемых текстов. |
|
|
Статистическая обработка полученных количественных данных. |
|
|
Интерпретация полученных данных на основе задач и теоретического контекста исследования. |
Контент-анализ состоит из ряда этапов: отбора материалов, выбора единицы анализа, подсчета единиц и, наконец, интерпретации результатов. С точки зрения чистой методологии отбор материалов носит предварительный характер. После определения темы происходит определение потенциального круга источников, в которых может находиться интересующая информация. Затем из этой информации отбирается та, которая содержит значимую с точки зрения исследования информацию. Отобранные материалы далее анализируются. В классических описаниях метода оговаривается, что при большом объеме более или менее однородных источников допустим анализ не всего массива информации, а только части её.
Описывая процедуру контент-анализа, можно выделить несколько этапов, а именно:
1-й этап исследования : Определение задач, теоретической основы и объекта исследования, разработка категориального аппарата, набор соответствующих качественных и количественных единиц.
Данный этап непосредственно связан с составлением программы исследования. Он носит характер качественного анализа, который подготавливает перевод смыслового содержания текста в цифровое выражение для его последующего количественного анализа. В этих целях на основе задач и теоретического контекста осуществляется выбор объекта исследования и определяются конкретные единицы анализа.
2-й этап : Составление кодировочной инструкции.
На этом этапе осуществляется соотнесение категорий и подкатегорий контент-анализа с конкретными содержательными элементами текста, т.е. происходит отыскание в тексте индикаторов выбранных категорий исследования. Здесь либо составляется соответствующий словарь индикаторов категорий, либо даётся развёрнутое описание категорий в терминах исследуемых текстов. Все категории и подкатегории контент-аналитического исследования кодируются, т.е. им даются определённые цифровые или буквенные обозначения, что составляет код данного исследования. Всё это входит в кодировочную инструкцию. В неё также включается обозначение знака информации. Он обычно определяется как "положительное", "отрицательное" и "нейтральное" отношение, что соответственно кодируется как +, -, 0.
Составление кодировочной инструкции имеет очень большое значение, так как по существу в ней находят своё конкретное выражение основные положения методики исследования. Кроме соответствующего определения категорий и подкатегорий и других единиц анализа в кодировочную инструкцию включаются правила кодирования, оговариваются спорные случаи и т.д. При составлении конкретного кода в категориях предусматривается подкатегория "другое", в которую включаются те индикаторы данной категории, которые не вошли в выделенные подкатегории, но тем не менее являются её референтами и поэтому должны быть зафиксированы в частоте (и объёме) её упоминаний. Необходимость включения подкатегории "другое" вызывается тем, что заранее невозможно, а часто и не нужно предусматривать все подкатегории.
3 -й этап: Пилотажная кодировка текста
На данном этапе осуществляется кодировка части исследуемого массива текстов с целью апробации методики, изложенной в кодировочной инструкции. Кодировка текста представляет собой процедуру непосредственного перевода качественных, смысловых единиц (категорий, подкатегорий) через нахождение их индикаторов в тексте в количественные единицы, т.е. перевод текстов в условные обозначения - коды (цифры или буквы, которыми обозначены в кодировочной инструкции те или иные подкатегории). Подобная пилотажная кодировка даёт возможность проверить надёжность методики, т.е. испытать её на обоснованность (соответствие задачам и теоретическим понятиям исследования) и устойчивость (воспроизводим ость результатов)
Обоснование полноты объёма выделяемых смысловых единиц доказывается следующим образом: выделяются все смысловые единицы из первого анализируемого текста, затем из второго текста - те же единицы плюс ранее не встречавшиеся, из третьего документа - те же, что встречались в двух предыдущих, плюс дополнительные и т.д. После изучения 3-5 очередных текстов, в которых не попадается ни одной новой единицы, ранее не фиксированной в предыдущих документах, можно полагать, что "поле" смысловых единиц из изучаемого материала исчерпано.
Устойчивость данных определяется при помощи повторного кодирования тех же документов тем же кодировщиком ("устойчивость во времени") или разными кодировщиками по единой инструкции ("устойчивость среди аналитиков").
4-й этап : Кодировка всего массива исследуемых текстов.
Осуществляется процесс квантификации, т.е. перевод в цифровое выражение всей совокупности исследуемых текстов. Регистрация частоты (и объёма) упоминания категорий и подкатегорий контент-анализа может производиться либо в заранее подготовленных таблицах, либо на отдельных карточках и перфокартах.
5-й этап: Статистическая обработка полученных количественных данных.
Эта обработка осуществляется вручную или на ЭВМ. Нередко оба эти способа используются одновременно в сочетании. Существуют специальные компьютерные программы, помогающие осуществить анализ более оперативно, такие как Контент-анализ 1.6, WINMAX, ATLAS/ ti, NUDIST, а также AQUAD, CAQDAS, ETHNOGRAPH.
,
Статистическая обработка цифрового материала, полученного в процессе кодировки, не отличается фактически по своим методам от статистической обработки данных, полученных в других видах социально-психологических исследований. Обычно используются процентные и частотные распределения, разнообразные коэффициенты корреляций и т.д. Вместе с тем используются и особые способы количественной обработки данных (см. формулу "удельного веса" смысловых категорий в общем объёме текста, предложенную А.Н. Алексеевым).
6 -й этап: Интерпретация полученных данных на основе задач и теоретического контекста исследования.
На данном, последнем этапе исследования, как и на первом, связанным с составлением программы, особенно ярко выступает качественная сторона контент-анализа в отличие от количественного аспекта, преобладающего на промежуточных этапах. Для адекватной интерпретации результатов и их соотнесения с данными, полученными с помощью других методов, особенно большое значение имеет учёт более широкого теоретического и социального контекста.
Формализованность, систематизированность и строгость контент-анализа проявляется в следующем. Прежде, чем непосредственно анализировать текст документа, исследователь определяет категории анализа, т.е. ключевые понятия (смысловые единицы), имеющиеся в тексте и соответствующие тем дефинициям и их эмпирическим индикаторам, которые зафиксированы в программе исследования. При этом желательно избежать крайностей. Если за категории анализа будут приняты слишком общие (абстрактные) понятия, то это предопределит поверхностность анализа текста, не позволит углубиться в его содержание. Если же категории анализа будут предельно конкретными, то их окажется слишком много, что приведет не к анализу текста, а к его сокращенному повторению (конспекту). Нужно найти золотую середину и постараться достичь того, чтобы категории анализа были: а) уместными, т.е. соответствовали решению исследовательских задач; б) исчерпывающими, т.е. достаточно полно отражали смысл основных понятий исследования; в) взаимоисключающими (одно и то же содержание не должно входить в различные категории в одинаковом объеме); г) надежными, т.е. такими, которые не вызывали бы разногласий между исследователями по поводу того, что следует относить к той или иной категории в процессе анализа документа.
Единицы контент-анализа После определения системы категорий анализа выбирается соответствующая им единица анализа текста.
Богомолова Н.Н. И Стефаненко Т.Г. предлагают разделять единицы контент-анализа на две большие группы:
качественные
количественные .
Качественные единицы контент-анализа отвечают на вопрос, ЧТО надо считать в тексте, а количественные единицы отвечают на вопрос, КАК надо считать.
К качественным предлагают отнести категории и их референты в тексте (индикаторы). Следует обратить внимание на то, что для обозначения различных единиц контент-анализа используются разнообразные термины, лишь основная единица контент-анализа - категория - признаётся всеми авторами. Большой разнобой в терминологии при обозначении различных единиц контент-анализа в определённой степени затрудняет понимание процедуры данного метода.
Категории могут подразделяться на более мелкие качественные единицы - подкатегории. Индикаторами категорий называются те элементы текста, те единицы содержания, которые служат референтами, качественными признаками соответствующих категорий и подкатегорий. В зависимости от специфики исследования индикаторы категорий могут выражаться в виде отдельных слов, словосочетаний, суждений, тем и т.д.
За единицу анализа может быть принято: а) слово б) предложение в) тема г) идея д) автор е) персонаж ж) социальная ситуация з) часть текста, объединенная чем-то, что соответствует смыслу категории анализа
Когда контент-анализ выступает единственным методом информации, оперируют не одной, а сразу несколькими единицами анализа.
При использовании самой простой единицы анализа, слова, очень легко потерять контекст упоминания. Прямой подсчет количества упоминаний дает так называемые «простые частоты». Однако для сравнения, например, количества упоминаний такой показатель не подходит в силу того, что является нестандартизированным. Возникает необходимость использования «относительных частот», т.е. количество упоминаний на какую-либо единицу текста (общее число слов в публикациях, тысячу слов, количество предложений, абзацев, публикаций и т.д.).
Количественными единицами контент-анализа являются единицы счёта и единицы контекста.
Единицы контекста используются для обозначения того сегмента текста, в пределах которого определяется частота упоминания соответствующих категорий и подкатегорий. Единицей контекста может служить предложение, статья, ответ на вопрос анкеты, интервью и т.д. Затем устанавливаетсяединица счета , т.е. количественная мера единицы анализа, позволяющая регистрировать частоту (регулярность) появления признака категории анализа в тексте. Единицами счета могут быть число определенных слов или их сочетаний, количество строк, печатных знаков, страниц, абзацев, авторских листов, площадь текста, выраженная в физических пространственных величинах и многое другое.
Богомолова Н.Н. И Стефаненко Т.Г. выделяют два вида подсчётов частоты упоминаний категорий и подкатегорий при квантификации: а) сплошной, терминологический, б) сегментарный, типологический.
При сплошном подсчёте регистрируются, а потом подсчитываются все появления индикаторов данной категории или подкатегории. При сегментарном, тематическом подсчёте упоминаний категорий регистрируется лишь первое появление данной категории в единице контекста, а повторные упоминания этой категории в данной единице контекста не учитываются.
Единицей счёта может быть объём - физическая протяженность или площадь текстов, заполненная смысловыми единицами. Объём упоминаний категорий может измеряться различными способами: подсчётом числа строк, печатных знаков, квадратных сантиметров площади, посвященных данной категории и т.д.
В основу системы кодирования должна быть заложена по крайней мере одна (или несколько) из следующих четырех характеристик содержания текста: частоты, направленности, интенсивности и пространства. Как уже отмечалось выше, чаще всего измеряют частоту и объём занимаемого пространства. В исследовательском проекте, основанном на контент-анализе, исследователь может замерить как одну, так и все четыре характеристики. Поясним, что собой представляет каждая из них.
Частота. Это всего лишь фиксация и подсчет, имеет ли нечто место или нет, а если да, то как часто. Например, сколько пожилых людей появляется в телевизионных программах на протяжении одной недели? Какова их доля среди всех персонажей? Или же какова доля этих программ среди остальных?
Направленность. Речь идет об указании направления сообщений внутри содержания некоего континуума (их позитивный или негативный, поддерживающий или опровергающий характер). Например, исследователь может разработать перечень способов показа ситуаций, в которых действуют пожилые люди. Способы эти могут быть позитивными (например, дружелюбный, мудрый, уравновешенный человек), либо негативными (например, непристойный, тупой, самовлюбленный).
Интенсивность. Это сила или мощь сообщения в заданной направленности. Например, негативная характеристика забывчивости может быть смягчена (забыл взять ключи, уходя из дома; не сразу вспомнил имя человека, которого не видел несколько лет) или преувеличена (не помнит, как его зовут, не узнает своих детей).
Пространство. Исследователь может зафиксировать размер сообщения или количественно охарактеризовать пространство, им занимаемое. Пространство письменного текста измеряется путем подсчета слов, предложений, абзацев или места, отведенного сообщению на странице (например, в квадратных дюймах или сантиметрах). Для измерения видео- и аудиотекстов можно использовать количественные характеристики времени. Например, персонаж может присутствовать в течение нескольких секунд или появляться периодически в каждой сцене двухчасовой программы.
В общем виде процедуры подсчёта при контент-анализе аналогичны стандартным приёмам классификации по выделенным группировка, ранжирования и шкального измерения. Для исчисления результатов контент -анализа используются и специально разработанные формулы.
А.Н. Алексеев предложил для оценки "удельного веса" смысловых категорий в общем объёме текста следующую формулу, указывающую на уровень интенсивности представленной в тексте определённой темы:

Укс - "удельный вес" данной смысловой единицы
Кгл - число случаев, когда смысловая единица оказалось главной
Квт - число случаев, когда та же единица оказывается второстепенной
E - сумма анализируемых текстов (документов)
Специальным способом, разработанным для нужд контент-анализа, является методика Ч. Осгуда анализа зависимости элементов для расчёта совместной встречаемости различных элементов в тексте. Процедура данной методики состоит в том, что после подсчёта совместной встречаемости единиц анализа, рассчитывается квадратная матрица возможных и фактических совместных появлений этих единиц в тексте.
Контент-анализ
Это первая статья на моём блоге о контент-анализе, и она даёт общее представление о методе контент-анализа. Перевод с английского мой. Приятного прочтения.
Бернард Р Берелсон (1912-1979)
Контент-анализ – это детище эры электроники. Вместе с тем контент-анализ регулярно проводился уже в 1940-е года и ещё стал более часто используемым и пользующимся доверием методов с середины 1950-х годов, когда исследователи стали опираться не на слова, а на оперирование отдельными тематико-семантическими структурами, их стали интересовать связи между этими смыслами [корреляции], а не простое присутствие слов в массивах текстов.
Области использования контент-анализа.
Благодаря тому, что контент-анализ может быть использован для изучения любого по содержанию и форме текста или массива текстов или другой форме записи коммуникации, метод применяется в самых разных областях, например в сфере маркетинга и области изучения СМИ, литературе и риторике, этнографии и культурологи, в дисциплинах, изучающих гендерн и возраст, социологии и политологии, психологии и когнитивных науках и в других исследовательских областях знания и науках. Также контент-анализ тесно связан с социо- и психолингвистикой, он играет ключевую интегральную роль в системах разработки искусственного интеллекта. Нижеследующий список, опирающийся на труды Берелсона, описывает и другие категории сфер применения контент-анализа:
- Даёт возможность понять интернациональные различия в коммуникациях
- Определяет присутствие материалов пропагандистского характера
- Идентифицирует намерения и тенденции в индивидуальной или групповой коммуникации
- Описывает поведенческие реакции в рамках коммуникаций
- Определяет психологический и эмоциональный фон отдельных индивидов и групп
Типы контент-анализа
Существуют две основные категории контент-анализа: концептуальный (понятийный) [в русскоязычных материалах его принято называть количественным, независимо от семантического неравенства терминов] и корреляционный. Концептуальный ориентирован на идентификацию присутствия и частоту появления этих концептуальных единиц [единиц счёта]. Корреляционный анализ ориентирован на идентификацию связей между отдельными единицами счёта в рамках текста.
Концептуальный контент-анализ
Традиционно контент-анализ рассматривался только в качестве концептуального его варианта. В концептуальном анализе концепция [единица счёта] выбрана как средство изучения текста с помощью подсчёта частоты её появления в тексте. Поскольку единицы счёта могут проявляться как эксплицитно так и имплицитно перед началом квантификации единиц важно заранее чётко определить и зафиксировать варианты имплицитного проявления единиц счёта. Для того чтобы избежать субъективности в определении объектов в качестве единиц счёта на данном этапе принято использовать специальные словари контент-анализа [тезаурусы].
Как и во многих других методах, концептуальный контент-анализ начинается с определения ключевых вопросов исследования и выборки или выборок. Будучи выбранным для анализа текст должен быть закодирован в рамках установленной исследователем системы категорий. Процесс кодирования представляет собой процесс сокращения объёма материала, являющийся основной идеей контент-анализа. Разделение массива текста на отдельные тематически целостные и релевантные категориальному аппарату единицы информации позволяет идентифицировать определённые характеристики материала, анализировать и интерпретировать их.
Примером концептуального анализа может являться изучение текста посредством подсчёта встречаемости кодов входящих в словарь контент-анализа кодов. В рамках анализа исследователь должен, например, ставить вопрос о том, как часто в тексте встречаются слова, подтверждающие ту или иную позицию, и как часто встречаются слова, её опровергающие. Исследователь должен быть заинтересован только лишь в подсчёте этих слов, но не в идентификации семантических и тематических связей между ними, что характерно для корреляционного анализа. В концептуальном анализе исследователь изучает только присутствие объектов релевантных вопросам исследования, то есть определяет – что в большей мере представлено в тексте – подтверждение той или иной гипотезы или гипотез или её (их) опровержение.
Корреляционный контент-анализ
Как уже было сказано выше, корреляционный контент-анализ базируется на принципах концептуального контент-анализа, изучая связи между единицами счёта (концепциями, позициями). И как в случае с другими типами исследований, данный подход базируется на определении выборки и категорий анализа, операционализированных словарём контент-анализа, что и определяет дальнейших ход исследования. Для корреляционного контент-анализа определить какие типы позиций (единиц счёта) будут эксплуатироваться в рамках исследования. Проводились исследования с использованием всего нескольких таких позиций (concepts) и проводились с использованием более 500 категорий концепций. Очевидно, что слишком большое число категорий может дать некорректные результаты исследования, так как с увеличением числа категорий и единиц счёта растёт и сложность анализа. Такое же утверждение характерно и для слишком маленьких категориальных аппаратов и словарей, дающих при использовании ненадёжные и потенциально некорректные результаты. Таким образом, при создании словарей и категориальных аппаратов важно опираться на особенности анализируемого массива и на конкретные задачи замера.
Существует большое количество методик проведения корреляционного контент-анализа, что определяет гибкость и популярность метода. Исследователи могут самостоятельно разрабатывать собственные методики проведения корреляционного контент-анализа в соответствии с задачами конкретного исследования. Когда разработанная процедура в достаточной мере доказала свою эффективность и объективность, она может быть принята и распространена среди других исследователей. Процесс проведения корреляционного контент-анализа достиг высокого уровня развития в компьютерной среде – среде автоматизации расчетов, но, даже не зависимо от этого, как и многие другие методы исследований, он является весьма длительным, требующим массу времени на реализацию. Вероятно, самым серьёзным требованием к этом методу является необходимость соответствия строгим статистическим нормам при условии сохранения богатства материала, выраженного в отдельных деталях, требующих качественного подхода для анализа.
Вопросы надёжности и верификации
Вопросы надёжности и верификации актуальны и в рамках данного метода. Надёжность результатов контент-анализа опирается на однородность процесса изучения, его стабильность (stability), умении кодировщиков и интерпретаторов оперировать данными единым образом на протяжении всего исследования; воспроизводимость или умение группы кодировщиков классифицировать материал в соответствии с заданным категориальным аппаратом единым образом; высокая статистическая точность классификации материала в соответствии с заданными категориями.
Ключевой проблемой концептуального контент-анализа является проблема получения спорных, сомнительных результатов, что является следствием использования самих процедур метода. Главный вопрос в данном контексте – какой объём и уровень заложенного в тексты смысла объективно доступен для идентификации, или, другими словами, являются ли полученные данные результатом использования исключительно введённого инструментария либо они получены и при участии других факторов, повлиявших на результаты исследования? При этом едва ли можно представить себе различные варианты толкования, например, числа 99 в точных науках. Объективные результаты исследования можно получить при использовании только основных [репрезентативных тематически, релевантных теме замера] материалов, массивов текстов, но и при этом, вопрос об объективности и возможности верификации и обоснования результатов остаётся открытым и злободневным.
Обобщения, заключения исследователей во многом зависимы от того, как конкретно исследователь определяет для себя значение той или иной категории, равно как актуальна и надёжность самого категориального аппарата. Исследователь обязательно должен точно определить категории и единицы счёте которые позволят объективно замерить исследуемый объект. Аналогично, точнейшим образом необходимо создать объективную системы правил и инструкция для исследования. Разработка правил, которые позволят всем кодировщикам и интерпретаторам следовать единым стандартам в работе, одинаковым образом кодировать материал, жизненно важна для успеха в проведении концептуального контент-анализа. Воспроизводимость [объективный выбор инструментов анализа, в случае необходимости выбранный идентично в рамках аналогичного исследования] и точность, не только категорий анализа и единиц счёта, но и ключевых подходов к анализу материала, позволяют получать более корректные и надёжные результаты.
Один из первых трудов по контент-анализу: Б.Берелсон "Формирование политических предпочтенией на президенских выборах"
Преимущества контент-анализа
Контент-анализ имеет ряд серьёзных преимуществ перед другими методами и просто очевидных достоинств. Среди них стоит выделить:
- Изучает непосредственно саму коммуникацию через анализ текстов, что позволяет исследователю взаимодействовать с первичным средством коммуникаций в социуме
- Работает как с качественными, так и с количественными данными
- Может дать ценную историческую/культурологическую информацию, описывающую разные исторические периоды, опираясь только на анализ текста
- Позволяет получать информацию близкую по форме изложения [текст], хотя степень такой близости варьируется в зависимости от используемого инструментария
- Может быть использован для анализа материала, необходимого как средства развития тех или иных систем
- «Ненавязчивый» способ анализа коммуникаций [участники коммуникации в данном случае не испытывают при анализе никакого дискомфорта, так как метод не вмешивается непосредственно в коммуникации]
- Комплексно, интегрально и вдумчиво, глубинно подходит к изучению моделей человеческих мыслей и языка
- Если метод используется корректно, то он расценивается в качестве объективного (базируется на реальных фактах, в отличие от дискурсивного анализа)
Недостатки контент-анализа
- Контент-анализ также имеет и ряд недостатков, как теоретического так и прикладного характера:
- Может потребовать очень много времени на проведение замера
- Потенциально опасный для допущения ошибки, в особенности если используется корреляционный анализ, ориентированный на идентификацию глубинных данных
- Часто не имеет теоретической базы в рамках различных методик проведения, либо, ради достижения важных для исследования результатов, может игнорировать теоретические научные ориентиры
- По своей природе – редуктивен, то есть ориентирован на игнорирование слабо проявленной информации, в особенности, если производится анализ сложных по содержанию текстов
- Часто ориентирован на упрощение результатов, так как опирается на простой подсчёт слов
- Нередко игнорируется контекст содержания единиц счёта (слов), либо нивелируется значимость последующих слов
- Может быть непрост для применения компьютерных технологий и автоматизации исследования
Оригинал статьи находится по следующему адресу: http://www.gslis.utexas.edu/~palmquis/courses/content.html
(перевод Алексея Рюмина)
-
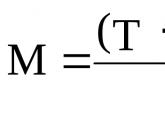 Методика расчета производственной мощности в непрерывных химических производствах
Методика расчета производственной мощности в непрерывных химических производствах
-
 Уильям Генри Фокс Толбот — изобретатель калотипии и бумажных фотографий
Уильям Генри Фокс Толбот — изобретатель калотипии и бумажных фотографий
-
 Методы измерения твердости материалов по виккерсу, бринеллю, роквеллу Метод виккерса достоинства и недостатки
Методы измерения твердости материалов по виккерсу, бринеллю, роквеллу Метод виккерса достоинства и недостатки
-
 На сколько могут задержать зарплату работнику по закону?
На сколько могут задержать зарплату работнику по закону?
Популярное
- Как происходит миграция птиц?
- Open Library - открытая библиотека учебной информации
- Организация производства на предприятии -основные понятия теории организации производства -основные принципы организации и функционирования производства
- Самые высокооплачиваемые профессии в россии
- Как участвовать в тендерах и получать самые выгодные контракты Участие в закупках с чего начать
- Разница между горячекатаной и холоднокатаной сталью Сталь группы А
- В чем заключаются обязанности упаковщика и фасовщика В чем заключается работа упаковщика
- Инструкция по ведению делопроизводства в бюджетных учреждениях Делопроизводство в бюджетном учреждении
- Отказывают предоставить отпуск: что делать?
- По заполнению формы федерального статистического наблюдения